
A dummies guide to machine learning
The world of artificial intelligence is an interesting place to be a part of these days. Due to the cheap and ubiquitous access to computing power in form of CPUs and GPUs has made it easier for researchers and organizations to harness the power of predictive modelling and analysis.
In order to understand the nature of the problem, I typically ask the following questions:
- What is the nature, size and quality of your data?
- What hardware do you have to run the model?
- What are you trying to find? (if you don’t know what you’re looking for then yer dun goofed!)
But in order to understand when to use a model from the plethora of options we need to know the types of problems we can solve and in which category your problem falls under.
Machine Learning falls under the following 5 categories: Supervised learning, Unsupervised learning, Semi-supervised learning, Reinforcement learning and Recommendation Engine.
In Supervised learning we have labelled data. If we have categorical data we can use classification algorithms if the data is continuous we are better off with regression. Anomalies fall under anomaly detection.
In Unsupervised Learning our data is non-labelled and we need to make sense of this data by putting them in clusters i.e. clustering or reduce the dimensions to find the meaningful ones using association rules.
Semi-supervised Learning contains a mix of labelled and unlabeled data.
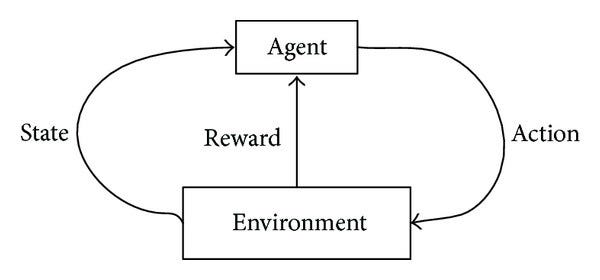
In Reinforcement Learning we could have both types of data. The model takes an action to maximize the reward function in an environment.
Reinforcement learning can be better explained by reward feedback or the reinforcement signal.
Recommendation Engine is an approach where the algorithm finds patterns in historical data to give accurate and meaningful recommendations. Due to its complexity I like to give Recommendation Engine its own category!
Popular Machine Learning Algorithms
- Linear Regression: Estimating coefficients of a model to predict an output with a given input.
- Logistic Regression: Estimates coefficients like LR but uses maximum-
likelihood estimation. - Decision Trees: Uses greedy algorithm on the training data to estimate splits in the tree.
- Naive Bayes: A probabilistic model used for both binary and multi-class classification.
- k-Nearest Neighbors: KNN model generates predictions by calculating similarity between train and test data.
- Learning Vector Quantization: LVQ model is an artificial neural net (ANN) algorithm that makes predictions like KNN but learns from the training set.
- Support Vector Machines: SVM model uses different types of classifiers (maximal-margin, soft margin) and converts the data into a kernel (linear, polynomial, radial) to made predictions.
- Random Forests: RF combines predictions from multiple variance models using bagging techniques (also known as Bagged Random Forests).
- Boosting: Boosting (AdaBoost or XGBoost)adds weak learners to correct
classification errors to make accurate predictions.