
A dummies guide to gradient descent and backpropagation
A lot of data scientists use the term Gradient Descent and Backpropagation interchangeably, but contrary to popular opinion they are not the same thing.
What is Gradient Descent?
Gradient Descent is an optimization technique in the machine learning process which minimizes the cost function. Every machine learning algorithm has a cost function.
What is the Cost Function and why do I need to minimize it?
Whenever we use machine learning algorithms we are using the training data to make predictions which we later compare with the test data. The cost function is used to inform us how close are the real values from the training data to the predicted values in the test data. The closer the values, the lesser the accuracy error and the better our algorithm’s prediction prowess.
Gradient Descent is essentially an optimization algorithm we use in machine learning which helps us find the minimum point in the cost function (local minima or global minima). Think of gradient descent as a detective which is trying to find where the minimum point of the cost function. The minimum point of the cost function would mean the least amount of error.

If we map all the values of the cost function, we will see something like a 3D model akin to an undulating plane or mountain. Gradient descent is the method which is trying to find the lowest point in the 3D model. Again, the lowest point would mean for us the least error for our model. You can also picture gradient descent as a hiker trying to find the plateau on a hill. If the hiker finds the plateau he can’t go any lower. Similarly, if the gradient descent algorithm finds the minimum point, it will stop and wont go any further. We can then say that our model has converged.
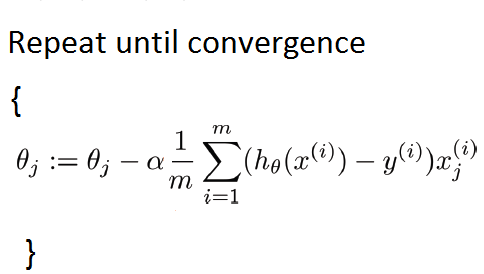
The alpha (learning rate) in the formula is how fast the algorithm converges. basically, we can control how slow or fast the hiker can go down the hill. If the learning rate is too small the hiker will very very slow and wont be able to reach the plateau. Similarly, if the learning rate is too large the hiker may walk past the plateau! The method by which the gradient descent algorithm works is by calculating derivatives which measures the rate of change of a slope.
What is Backpropagation?
In simple English, backpropagation is the method of computing the gradient of a cost function in deep neural nets. Unlike the gradient descent algorithm, backpropogation algorithm does not have a learning rate. Backpropagation instead finds the partial derivatives of the cost function.
In neural nets we have input layers for our input features, hidden layers to transform the inputs for our outputs and output layers for our desired outputs. Each neuron in the neural network has a corresponding weight and we change the weight to improve our performance. If by changing the weight we can improve the performance of the neural net we save that particular weight. To change one weight the neural net has to perform forward passes depending on the number of the hidden units, this is a slow and inefficient process. This is why we use backpropagation. Backpropagation allows us to compute the error derivatives of all hidden units at the same time.
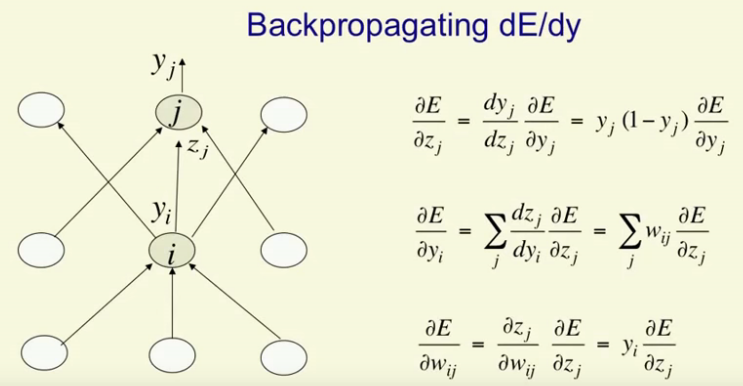
From the picture we can see that backpropagation works like forward pass but moves backwards from the hidden layer (i) to the input layer (j) and combines the error derivatives of all hidden layers at once. Backpropagation saves us time and helps us update the weights faster.
Conclusion
In a nutshell, the backpropagation algorithm computes how the error changes as we changes the weights in the neurons while the gradient descent algorithm optimizes the error of the cost function. In deep neural nets we use gradient descent and backpropagation in tandem to create the best models.