
Cheat sheet for machine learning
Pro Tip: Print this out and put it on your desk or place of work for quick reference
Machine learning Algorithms
Supervised learning: Logistic Regression, Linear Regression, Neural Nets, Support Vector Machines
Unsupervised Learning: K-Means Clustering, Principal Component Analysis, Anomaly Detection
Linear vs Logistic Regression
Linear Regression: In linear regression, the outcome (dependent variable) is continuous. It can have any one of an infinite number of possible values.
Logistic Regression: The outcome (dependent variable) has only a limited number of possible values.
When to use SVM vs Logistic Regression
n = number of features
m = number of training examples
if n is large (relative to m) = use logistic regression on SVM without a kernel (linear kernel)
e.g. n = 10,000 , m = 10–1000
if n is small, m is intermediate = use SVM with Gaussian kernel
e.g. n = 1–1000, m = 10–10,000
if n is small, m is large = use logistic regression or SVM without a kernel (linear kernel)
e.g. n = 1–1000, m = 50,000 +
Neural nets can work too but will be slower to train
Neural Nets
Number of input layers = number of features
Number of output layers = number of
Principal Component Analysis
Summarises features by giving it a new characteristic. The one of the main goal of the multivariate analyses (like PCA) is to decrease the dimensions (variables=coordinates) but keep the most of the variance of the data.
Cost/Loss function
Describes how well the model fits the data. It’s included in most algorithms.
Regularisation (e.g. Gradient Descent)
Used to solve overfitting. Add more features with the objective function. Hence, it tries to push the coefficients for many variables to zero and hence reduce the cost function.
Overfit/Underfit
Overfit means fits all points on graph, underfit means fits a few points on graph
Backpropagation
Back propagation is just a special name given to finding the gradient of the cost function in a neural network.
Cross-validation
Spitting data into training and test sets e.g. k-fold cross-validation
Errors (1&2 w/ example)
Type 1 Error: A man is pregnant
Type 2 Error: A pregnant woman is not pregnant (more dangerous)
Dimensionality reduction
Reduces number of features (loss of information)
Labels: What we are predicting
Features: Input variable describing data
Discrete Variable: Variables that can be counted
Continuous data: Variables that can be measured
Categorical variable: Categories e.g. male and female
Regression: Uses continuous values e.g. house pricing and square feet
Classification: Classifies into 2 groups e.g. Email spam or not spam
A simple linear equation is:
y =wx +b
where;
y = y-axis, x = x-axis,** w** = slope, b = y-intercept
However in machine learning;
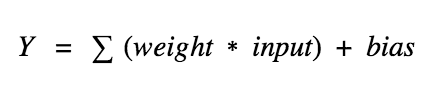
y^ = prediction, b= bias, w= weight of feature, x = feature
Goal: Minimize the difference between y and y^
Perfect Model: Loss will be equal to 0. Loss is characterised by MSE (Mean Squared Error)
Cost: Loss for the entire dataset
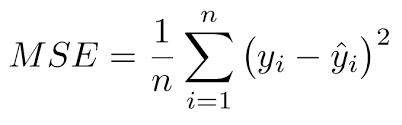
MSE: Sum squared loss of all examples / Number of examples
Goal in machine learning is to reduce loss
Gradient: Derivative of a loss function.
Gradient Descent: Descending to the converged model.
A good visual explanation can be found here
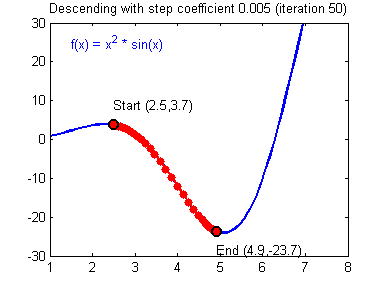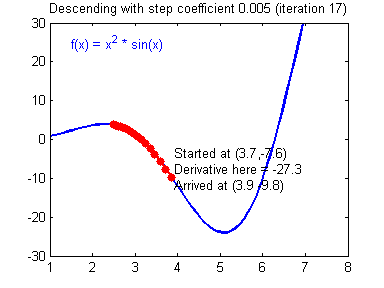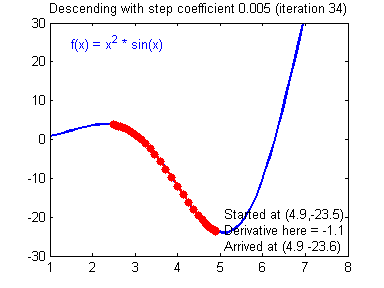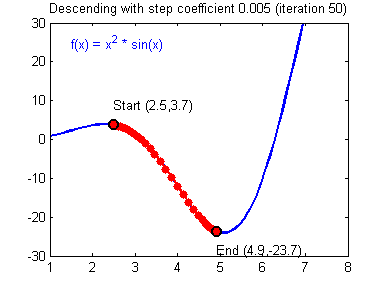
Learning Rate: The rate of Gradient Descent
Hyperparameters: Things you tune to increase accuracy of model e.g.
Learning Rate, No. of Iterations, No. of Hidden Units, Activation function, regularization, Type of Gradient Descent etc.
Stochastic Gradient Descent: 1 example used at a time
Mini-batch Gradient Descent: Batch (10–1000) loss + gradient averaged over the batch (more effective than Stochastic Gradient Descent)
Optimization methods: SDG, MDD, GDM, RMRProp, Adam, LRD
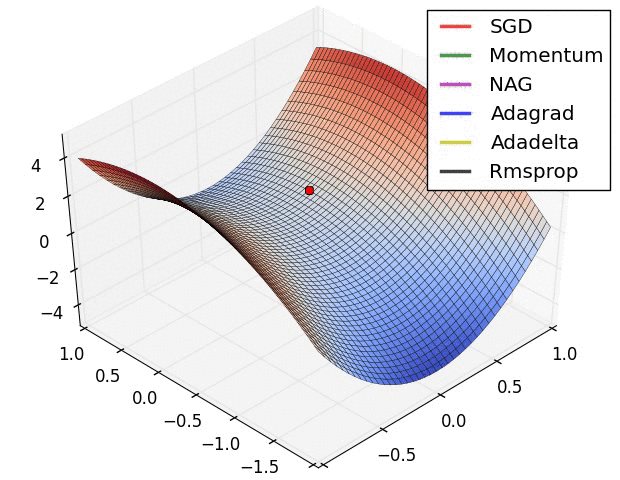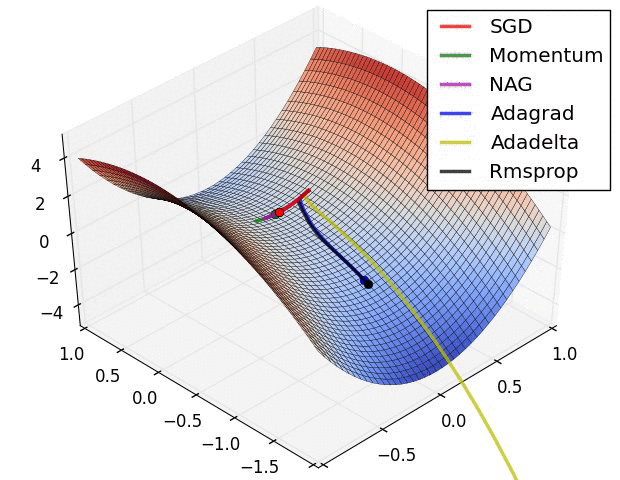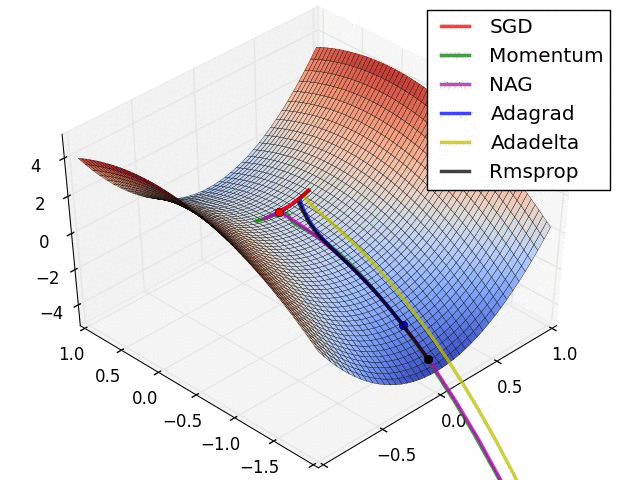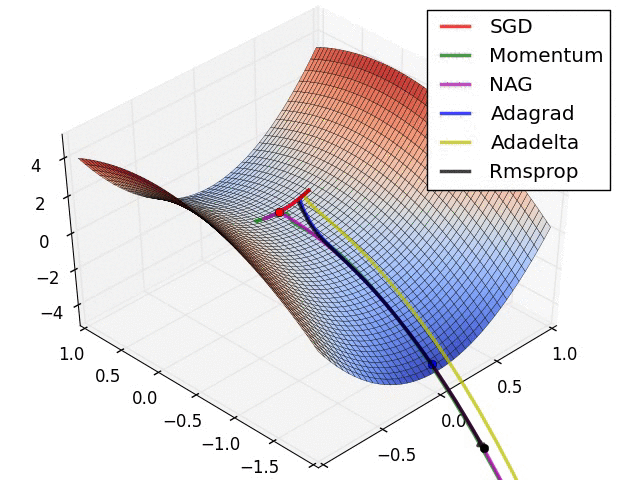
Goldilocks: Optimal learning rate
Data Split: training data, validation data, test data
Feature Engineering: Extracting features from data (Note: Features should have a good meaning).
Normalization: Use log of all features for normalization
Precision Recall: Better the PR value better the model. Must look at both values precision and recall.
Prediction Bias: If we do not have a 0 bias we have a problem
Activation functions: Non-linear functions e.g. relu, leaky relu, tanh all used for different types of problems
Softmax: Multiclass classifier
Regularization: Used to avoid overfitting e.g. L1 & L2
Static model: Trained offline
Dynamic model: Trained online
Autoencoder -> Encoder & Decoder
Encoder: Converts input data into new representation
Decoder: Converts new representation back into original data
Model should have low variance and bias
Google’s helpful glossary can be found here